3.1 Topología
Primero consideremos las propiedades y relaciones que encierran los conceptos de adyacencia y conectividad. Estas propiedades son “topológicas” en el sentido de que no dependen del tamaño o la forma; en el caso continuo, permanecen sin cambio bajo deformaciones continuas (rubber-sheet) arbitrarias. Para las definiciones básicas de estos conceptos ver Sección 1.7.
a. Etiquetado de componentes de
matrices
A menudo queremos tratar los componentes conexos individuales de un grupo S como objetos separados. La representación de colección de estos objetos es una imagen multivaluada en la cual los puntos de cada componente tienen un único nivel no nulo, y los puntos de Š tienen un valor cero. En los próximos párrafos discutiremos cómo construir esta representación a partir de una representación dada de S.
Si S está representada por una imagen binaria, podemos etiquetar sus componentes realizando dos rastreos fila a fila. Asumamos primero que queremos etiquetar componentes 4-conexos. Durante el primer rastreo, para cada punto P que tenga valor 1, examinamos a los vecinos de arriba y a mano izquierda de P; nótese que si existen, acaban de ser visitados por el rastreo, así que si son 1’s, ya han sido etiquetados. Si ambos son 0’s, damos a P una nueva etiqueta; si tan sólo uno es 0, le damos a P la etiqueta del otro; y si ninguno es 0’s, le damos a P (por ejemplo) la etiqueta del de la izquierda, y si sus etiquetas son diferentes, registramos el hecho de que son equivalentes, i.e., pertenecen a la misma componente. Cuando se completa este rastreo, cada 1 tiene una etiqueta, y no se ha asignado ninguna etiqueta a puntos que pertenezcan a diferentes 4-componentes; pero puede que se asignen muchas etiquetas diferentes a puntos en el mismo componente (ver Fig. 16a y 16b). Ahora ordenamos las parejas equivalentes en clases de equivalencia, y escogemos una etiqueta para representar cada clase. Finalmente, realizamos un segundo rastreo de la imagen y sustituimos cada etiqueta por el representante de cada clase (Fig. 16c); cada componente ha sido ahora etiquetado de forma única.
Para etiquetar componentes 8-conexas, también examinamos a los dos vecinos superiores diagonales de cada 1; estos también han sido visitados por el rastreo. Si los cuatro vecinos son 0, el punto P consigue una nueva etiqueta; si uno de ellos es 1, P consigue la misma etiqueta; si dos o más de ellos son 1, P consigue una de sus etiquetas, y las equivalencias son registradas. (Sólo necesitamos notar esas equivalencias que no hayan sido todavía detectadas en posiciones previas de P; los detalles se dejan para el lector). El proceso de equivalencia y re-etiquetado se realiza como en el caso de 4-conexo. Alternativamente, podemos examinar a los vecinos izquierdos, superior, de arriba-izquierda de cada punto P, si P es 0 ó 1; si P es 1, procedemos como antes, y si P es 0 pero sus vecinos de arriba e izquierda son 1, notamos la equivalencia de sus etiquetas. Las Figuras 16d y 16e muestran los resultados de los primeros rastreos usando estos dos esquemas.
El proceso de etiquetado de componentes parece ser básicamente secuencial. Los algoritmos pueden ser ideados para etiquetar componentes usando un ordenador multiprocesador, pero no son muy eficientes. Por ejemplo, supongamos que primero le damos a cada 1 una única etiqueta, e.g, sus coordenadas en la imagen; esto puede realizarse en un número de pasos igual al diámetro de la imagen. Entonces podemos realizar repetidamente una operación de máximo local en paralelo, donde el máximo está definido por el orden lexicográfico de los pares de coordenadas; los puntos etiquetados 0 permanecen 0. Usamos el máximo 4-vecino si queremos etiquetar 4-componentes, y 8-vecinos para 8-componentes. Cuando se itera hasta que no haya más cambios, cada punto de una componente dada está etiquetados con las coordenadas de los puntos más altos de los más a la derecha. Sin embargo, el número de iteraciones requeridas puede que sea del orden del área de la imagen (considere un componente como una serpiente).

Fig. 16
Etiquetado de
componente. (a) Entrada S. (b) Resultado del primer rastreo, usando
4-conectividad para S; se indican las equivalencias descubiertas en cada fila.
(c) Resultado del segundo rastreo, reemplazando todas las etiquetas equivalentes
por una representativa. (d)-(e) Resultados del primer escaneo usando dos
versiones de el algoritmo de 8-conectividad (ver texto)
El etiquetado de los componentes puede llevarse a cabo simultáneamente para las componentes de S y Š, o de hecho para las componentes de los conjuntos en cualquier partición S1,..., Sm (e.g., la partición de una imagen arbitraria a en conjuntos de un nivel gris constante) usando 4- o 8-conectividad para Si’s en cualquier combinación.
b. Etiquetado de componentes en otras
representaciones
Una aproximación fila por fila para etiquetar las componentes de S (o de una partición arbitraria) puede fácilmente ser definida en el caso donde S es dada por su representación de longitud de secuencia. En la primera fila, cada secuencia de 1’s obtiene una nueva etiqueta. En las filas subsecuentes, comparamos la posición de cada secuencia r con aquellas de las secuencias de la fila precedente. Si r no es adyacente (4- u 8-) a ninguna secuencia de la fila precedente, consigue una nueva etiqueta. Si tan sólo es adyacente a una secuencia así, consigue la etiqueta de esa secuencia. Si es adyacente a dos o más de tales secuencias, consigue (por ejemplo) la primera de sus etiquetas, y notamos que todas sus etiquetas son equivalentes. Cuando todas las filas han sido procesadas, ordenamos las equivalencias y entonces realizamos un segundo rastreo para darle sus etiquetas finales a las secuencias.
Si S está representada por un árbol de cuadrados, podemos etiquetar sus componentes recorriendo el árbol en un orden estándar, por ejemplo NW, EN, SW, SE. Cada vez que lleguemos a un nodo hoja negro, visitamos los nodos hoja cuyos bloques colindan con los bloques de M en sus lados sur y este (o en la esquina sudeste, si estamos etiquetando 8-componentes); ver Sección 2.2f sobre cómo encontrar estos nodos. Si encontramos nodos hoja negros sin etiquetar, les damos las mismas etiquetas que a M; si encontramos nodos hoja negros que ya han sido etiquetados, notamos que sus etiquetas son equivalentes. Cuando el recorrido está completado, clasificamos las equivalencias, recorremos de nuevo el árbol, y damos a los nodos hoja negros sus etiquetas finales. El tiempo requerido es del orden del número de nodos del árbol veces la altura de árbol. Para los detalles de este algoritmo ver [66].
Para etiquetar las componentes basadas en la representación MAT, debemos comprobar todas las parejas de bloques que se superponen o son adyacentes (i.e., cuyos centros no están muy lejos de la suma de sus radios) para determinar las equivalencias de etiquetas. Los detalles de este proceso se dejan para el lector. Si se nos da una representación de borde, y sabemos cuáles son los bordes externos, podemos marcar los bordes en una matriz como en la Sección 2.2e, y dar a los puntos de cada borde externo una única etiqueta; estas etiquetas pueden entonces expandirse hacia el interior.
c. Cuenta de componentes
Una vez que hayamos etiquetado las componentes de S, sabremos cuántas componentes tiene, ya que es justo el número de etiquetas finales usadas. En esta subsección describimos un método de contar componentes sin etiquetarlos, basado en una operación de encogimiento paralelo [34, 37] adecuado para la implementación sobre un ordenador multiprocesador.
Supongamos que utilizamos 4-conectividad para S y 8- para Š. Si los vecinos de la derecha, de abajo y de abajo derecha de P son
P X
Y Z
definimos la operación Y tomando P como un 1 sii P + X = 2, P + Y = 2, o X + Y + Z = 3. Realmente, esto es equivalente a decir que
Si P = 1, tenemos Y (P) = 0 sii X = Y = 0
Si P = 0, tenemos Y (P) = 1 sii X = Y = Z = 1
Para cualquier subconjunto de T de la imagen, sea T1 el conjunto de 1’s que están o en T o inmediatamente encima y a la izquierda de T después de que Y sea aplicada y sea T0 el conjunto de tales 0’s. Se puede demostrar que si C es un 4-componente de 1’s, entonces C1 también, y si D es un 8-componente de 0’s, entonces D0 también(a menos que C o D consistan en tan sólo un punto, en cuyo caso C1 o D0 está vacío). Además, si C es 4-adyacente a D, entonces C1 es 4-adyacente a D0. De este modo, excepto para los componentes que constan de puntos solos, Y preserva las propiedades de conexión tanto de S como de Š.
Cuando se aplica Y repetidamente, se puede demostrar que cualquier componente C de S se encoge hacia el único punto (xc, yc), donde xc es la coordenada del punto más a la izquierda de C e yc es la coordenada de su punto más alto. Entonces este punto único desaparece. El número de pasos requeridos para que esto suceda es justo la distancia de bloque de ciudad más larga entre (xc, yc) y cualquier punto de C. Lo mismo es cierto también para cualquier componente de D de Š que no sea la componente de fondo. Una componente puede encogerse a un punto incluso si originalmente contiene agujeros, porque los agujeros encogen a puntos (que entonces desaparecen) antes de que lo haga la componente. Un ejemplo de la operación de Y se muestra en la Fig. 17.
Si usamos 8-conectividad para S y 4- para Š, se define Y para considerar a P como 1 sii P + Z = 2 o P + X + Y ³ 2. Esto es equivalente a
Si P = 1, tenemos Y (P) = 0 sii X = Y = Z = 0
Si P = 0, tenemos Y (P) = 1 sii X = Y = 1
Los resultados de aplicar esta Y repetidamente son exactamente análogos a los obtenidos más arriba. Por supuesto, podríamos haber definido Y usando otras vecindades 2 x 2 de P; estas Y’s encogerían las componentes hacia el nordeste, sudeste, o sudoeste mejor que hacia el noroeste. Un algoritmo de encogimiento simétrico, basado en vecindades de 3 x 3, se describe en [51].
Para contar componentes utilizando una operación Y, lo modificamos de forma que, en vez de desaparecer, los puntos aislados se convierten en marcas especiales, que no interfieren con el efecto de Y sobre los 1’s y los 0’s. Estas marcas se desplazan hacia la izquierda y hacia arriba a un contador en la esquina noroeste de la imagen. El número de iteraciones requeridas para encoger todos los componentes a puntos y contarlos de esta manera es menor que el diámetro de la imagen.
d. El género
Si todas las componentes de S están conectadas de una forma simple (i.e., no tienen agujeros), pueden utilizarse métodos especiales para contar las componentes. De forma más general, para cada S, se pueden usar métodos especiales para calcular el número de componentes de S menos el número de agujeros; este número se llama el género o número de Euler de S.
Si eliminamos repetidamente puntos simples de S en paralelo, se puede demostrar que cualquier componente simplemente conexa o encoge hacia un solo punto o desaparece. (Por ejemplo, cualquier componente de la forma
1 1 1 ... 1
1 1 1 ... 1
desaparece inmediatamente, ya que todos sus puntos son simples). Haciendo el borrado dependiente de la dirección, podemos garantizar que todas las componentes simplemente conexas encogen a un solo puntos; los detalles no se darán aquí. De este modo podemos contar las componentes simplemente conexas simples de S aplicando este proceso hasta que no haya más cambios y entonces contando los puntos aislados resultante moviéndolos a la esquina superior izquierda.
Hay varios métodos simples de calcular el género g(S) contando patrones locales de varios tipos en la imagen S. Usemos la siguiente notación (los espacios en blanco pueden ser 0’s o 1’s):
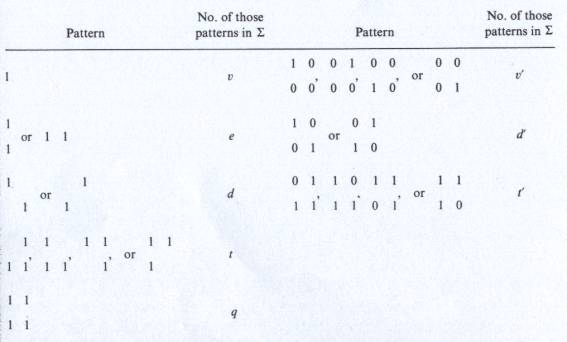

Fig. 17 Operación
de encogimiento Y. (a) Entrada S. (b)-(q) Resultados de aplicaciones
sucesivas.

Si utilizamos 4-conectividad para S y 8-conectividad para Š, entonces se puede demostrar [23, 37] que
g(S) = v - e + q = 1/4(v’- t’+ 2d’)
En el caso inverso tenemos
g(S) =
v - e - d + t - q = 1/4(v’- t’- 2d’)
Estos patrones pueden contarse en un rastreo fila a fila comparando cada fila con la precedente, o pueden convertirse en marcas especiales mediante operaciones lógicas paralelas, y las marcas podrán entonces ser movidas y contadas.
Las fórmulas con comillas recién dadas proporcionan un método muy simple de calcular el género a partir de los códigos de fisura de los bordes de S. De hecho, ambas fórmulas implican que 4g(S) es el número de esquinas convexas de S menos el número de esquinas cóncavas. Para ver esto, nótese que cada patrón v’ tiene una esquina convexa en su punto central; cada modelo t’ tiene una esquina cóncava; y cada modelo d’ tiene dos esquinas convexas si los 1’s adyacentes diagonalmente no están conectados, pero dos esquinas cóncavas si sí están conectados. Por supuesto, si sabemos qué bordes de S son bordes externos y cuales son bordes internos, podemos obtener g(S) simplemente sustrayendo el número de bordes internos del número de bordes externos.
Las fórmulas sin comillas pueden ser generalizadas al caso en el que S se representa por un árbol de cuadrados [14]. En particular, sea v el número de nodos hoja negros; e el número de parejas de tales nodos cuyos bloques son adyacentes horizontal o verticalmente; y q el número de tríos o cuartetos de tales nodos cuyos bloques se encuentren en y rodeen a un punto común, e.g.,
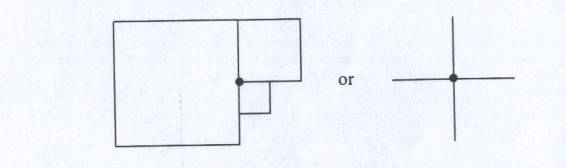
Entonces g(S) = v - e + q. Estas adyacencias pueden ser
encontradas (ver Sección 2.2f) recorriendo el árbol; el tiempo requerido es del
orden del número de nodos del árbol veces la altura del árbol.
Finalmente, damos una fórmula muy simple para calcular el género a partir de la representación de la longitud de secuencia de S. Para cada secuencia r, sea k(r) el número de secuencias de la fila precedente a la que r es adyacente; entonces g(S) = Sp(1 - k(r)).
e. Adyacencia, estar rodeado y
anidamiento
Dada cualquier partición de una imagen S, digamos S1, . . ., Sm, definimos el grafo de adyacencia (4- 8-) de la partición como el grafo cuyos nodos son los Si’s, y cuyos nodos Si y Sj están unidos por un arco si y sólo si Si es adyacente a Sj. Es sencillo construir este grafo rastreando S y comprobando los vecinos de cada punto para encontrar todas las adyacencias. Esta información es también fácil de obtener a partir de la representación de la longitud de la secuencia: se comprueban todas las parejas de secuencias consecutivas de cada fila, y se comprueban todas las parejas de secuencias de distinto valor en filas sucesivas buscando posibles adyacencias. Dada la representación MAT, comprobamos todas las parejas de puntos MAT de distinto valor buscando adyacencias (la distancia entre los centros igual a la suma de los radios). En la representación de árbol de cuadrados, para cada nodo hoja, comprobamos los nodos hojas cuyos bloques son adyacentes a él (Sección 2.2f). En una representación de borde la información estaría disponible inmediatamente, ya que para cada arco de borde debemos especificar qué pareja de regiones lo define.
En el párrafo precedente los grupos Si pueden ser o no ser conexos. (Dada cualquier partición S1, . . ., Sm podemos definir una partición refinada C1, . . ., CM consistente en las componentes conexas de Si’s). Un caso importante y especial es áquel en el que los Si’s son las componentes conexas de un conjunto S y su complemento Š, donde utilizamos 4-conectividad para S y 8-conectividad para Š o viceversa. La construcción del grafo es sencilla, una vez que hayamos etiquetado todas las componentes. No hay diferencia si usamos 4- o 8-adyacencia entre componentes, ya que como ya hemos señalado, si una componente de S y una componente de Š son 8-adyacentes, también son 4-adyacentes. En este caso, como hemos visto, los bordes son todos curvas cerradas. Además, puede demostrarse [55] que en este caso el grafo de adyacencia es un árbol. (Corolario: si C1, C2 son dos componentes cualesquiera de S, y D1, D2 dos componentes cualesquiera de Š, no podemos tener C1, C2 ambos adyacentes a cada uno de D1, D2, ya que de otra forma el gráfico contendría el ciclo C1, D1, C2, D2).
Recordamos (Sección 1.7b) que T rodea a S si cualquier camino desde S al borde de S se encuentra con T. También vimos (Sección 1.7c) que si C, D son componentes adyacentes de S, Š, respectivamente, entonces uno de ellos rodea al otro. De ahí que el árbol de adyacencia de los componentes de S y Š llegue a ser un árbol dirigido si utilizamos las relaciones adicionales de estar rodeado. Evidentemente, este árbol está enraizado en la componente de fondo de Š, que contiene el borde de S y que rodea así a todos los demás componentes de S y Š. Justo bajo la raíz tenemos componentes “continente” de S que son adyacentes al fondo; justo bajo ellos, componentes “lago” de Š; y justo bajo ellos, componentes “isla” de S; y así sucesivamente.
A menudo necesitamos conocer si uno o dos conjuntos rodean al otro, y en particular, si un conjunto dado S rodea un punto dado de P o Š. (En cartografía, esto se conoce como el problema de punto-en-polígono). Si se nos da la representación de matrices de S, este problema puede ser resuelto para todos los P simplemente etiquetando el componente de fondo de Š, por ejemplo con b’s; ahora, si P = 0 está rodeado por S, y si P = b no. Las representaciones de bloques maximales de S (secuencias, MAT, árbol de cuadrados) no parecen ser muy útiles en conexión con este problema§. Para representaciones de bordes, por otra parte, hay varios algoritmos [44] para decidir si P está dentro o fuera de una curva cerrada dada; utilizando tales algoritmos, podemos comprobar si P está dentro del borde externo de cada componente de S. Mencionamos aquí sólo una aproximación estándar: nos movemos hacia la derecha (por ejemplo) desde P, y contamos el número de veces que la curva es cruzada (pero no contamos las veces que la curva es sólo tocada sin ser cruzada), hasta que se alcanza el borde de S. Si el número de cruces es impar, P está dentro de la curva; si es par, P está fuera.
Si S1,..., Sm y T1,..., Tn son particiones de S, decimos que T1, ..., Tn es un refinamiento de S1, ..., Sm si todo Ti está contenido en algún Sj -de hecho, en uno único, ya que las S’s están desunidas. (Corolario: Cualquier Sj es una unión de Ti’s). La misma definición se usa en el caso más general donde T es un subconjunto de S, y S1,..., Sm y T1,..., Tn son particiones de S y T, respectivamente. Como ejemplo importante, es fácil demostrar que si T Í S, y S1,..., Sm y T1,..., Tn son las componentes de S y T, respectivamente, entonces T1,..., Tn es un refinamiento de S1,..., Sm. De este modo, e.g., si tomamos umbrales de S en s y en t, donde s £ t, y sean S, T los conjuntos de puntos por encima del umbral, toda componente de T está contenido en una única componente de S.
Supongamos que tenemos una secuencia de particiones Th1, . . ., Thnh, h = 1,2, ..., k, cada una de las cuales es un refinamiento de la precedente, y donde la primera partición es la trivial que consta de S en sí misma. De este modo cada Thi está contenido en un único Th-1, j, Definamos un grafo dirigido cuyos nodos son los Thi’s, y donde cada nodo está unido al nodo de la partición precedente que lo contiene. Este grafo es un árbol enraizado en T1 = S. Este árbol de refinamiento fue presentado en [29] para el caso en el que las particiones son las componentes de los puntos por encima del umbral en las series de umbrales 0 = t1 £ . . . £ tk (nótese que ya que t1 = 0, la primera partición consiste sólo en S).