Summary of Configuration Options
Appendix 1: Simple Spanish Grammar. Version 1
Appendix 2: Simple Spanish Grammar. Version 2
The characteristics of the system make it specially suitable for rapid prototyping of small-to-medium scale MT systems and for students of MT.
The system allows the user to define his/her own source language (SL) grammar with its corresponding lexicon, transfer module and target language (TL) grammar and lexicon. The syntax which the user must follow is described below under "Specification Languages".
Lekta may be used as a full MT system (i.e. performing the three translation phases) or as a parser only. As a full MT system, it may translate at a speed of up to 700 words per second.
The following sections illustrate the functioning of the system, configuration
options and simple examples.
^ [ ] , ~ | & + * ' " / ( ) { } : ; ! . < = > - %
Commands and reserved words won't be taken as identifiers either.
Commands: All the commands for Lekta are preceeded by the $ sign.
Reserved words: these are symbols with a special meaning within Lekta:
COHERENCE |
COMPLETENESS |
DO |
|
ELSE |
ELIM-PR |
GF |
HPATTERN |
IF |
NONULL |
NULL |
ON-NODE |
RG |
SELF |
THEN |
WHEN |
lekta [filename]If a filename has been specified, Lekta will execute all the instructions within the file.
If no file has been specified Lekta will run in interactive mode waiting for a command from the input device.
The start up file lekta.ini: Once invoked, Lekta looks for a file called lekta.ini in the working directory. If it already exists, all the instructions within the file will be executed. This option allows the user to have different configurations for different applications or developments and it provides great flexibility for the use of Lekta in a command sequence or pipe.
The following is an example of a lekta.ini file. Some of the commands will be clarified below.
% Load sp Language
$f "sp"
% Load eng Language
$f "eng"
% Configuration options
$c:apch
$c:apcp
$c:transl sp -> eng
$c:auo
$c:agen
$c:atra
Comments: There are two types of comments. The first type starts with a % sign and goes on till the end of line. The second type takes as the comment everything included within the sequences /% and %/.
Messages: The $m IDENTIFIER shows the identifier on the output device. This command can be used at any point and can be used as a first tracing device.
% The sp language specification
$$LANG sp
% Analysis grammar is loaded from file "Analysisrules.esp"
$f "Analysisrules.esp"
% Analysis Lexicon
% beginning of analysis lexicon
$al
$f "Analysis_lexicon.sp"
% End of analysis lexicon
$eal
% Transfer Spanish to English (language eng)
$t eng
$f "transfer.sp-eng"
$et
$$ELANG
%end of sp language
%Beginning of eng language
$$LANG eng % Generation grammar
$gg
$f "Generationrules.eng"
$egg
$gl
$f "Generation_lexicon.eng"
$egl
$$ELANG
$ag RGD GFD LPROD $eag- RGD defines the roots of the grammar, i.e. those nodes which may constitute an utterance. Its syntax is:
(RG: S NP VP)- GFD defines the grammatical functions of the grammar. Its syntax is:
Example:
(GF: subj obj obj2 xcomp)- The different productions that make up the grammar are shown with LPROD. This is a list of productions, each one with the following syntax:
Simple grammar of Spanish. Version 1.
$al LENTLEX $ealLENTLEX is a list of lexical entries. Each lexical entry consists of a feature structure, that is, a list of features separated by commas and within parentheses. Every feature has the following syntax:
ATTRIBUTE: VALUEATTRIBUTE is an identifier and VALUE can have any of the following values:
(LU: los, CAT:det, agr:(gen:masc,num:pl))
where agr stands for agreement, and so on.
For example, if the macro <MP> has been defined as
<MP> = (agr:(gen:masc,num:pl))The lexical entry for 'los' could be simplified as
(LU: los, CAT:det, <MP>)
In the LFG literature on there are several metavariables ( ^ and v, called UP and SELF) to refer to the production mother or daughter nodes. Thus, a classic LFG rule like:
^ subj = v ^ = v
(1 : S -> NP VP)
{ UP .subj = SELF-1;
UP = SELF-2}Each production may be associated with a group of functional equations in order to control the unifier´s performance. Their syntax is as follows.
In this example the feature structure associated with the production´s right-hand side SS (SELF-1) is passed directly to the symbol created by it (UP) while the feature structure associated with idiom (SELF-2) will be passed upwards as the idiom feature.(12 : SS -> SS idiom ){UP = SELF-1;UP.idiom = SELF-2 }
In addition, Lekta has been equipped with the following special functions:(87 : THOUSAND -> HUNDRED Q1000 HUNDRED){UP.quant = ((SELF-1.quant * SELF-2.quant) + SELF-3.quant)}
UP.pred = CONCAT(SELF-1.pred,^,SELF-2.pred)
IF MEMBER(obj, SELF-1.ggf) THEN ....
(1: SS -> QS){UP = SELF-1;IF ((SELF-1.subj.pred == NULL))THEN {UP.subj.pred = pro };IF (((SELF-1.agr.per == 1) &&(SELF-1.agr.per == 2)))THEN {UP.agr.per = 2 };UP.stype = quest}
The coherence test checks whether the grammatical function that is going to be created is compatible with the functions required by the subcategorization of the head as it appears in the ggf feature.(GF: subj, obj, obj2, acomp, ncomp, scomp, pobj)
The completeness test checks whether all the grammatical functions required by a verb are locally satisfied in the current the functional structure. Both tests ensure that there is no missing grammatical function required by the predicate or a grammatical function too many.ggf:[list of grammatical functions]
Our syntax has been enhanced so that the user may control a partial coherence or completeness. For instance, rule 23 below checks that all the grammatical functions local to the verb phrase have been completed but it also indicates that the subject doesn't have to be checked since it has not been consumed yet.
As indicated in rule 14, full completeness and coherence may be checked on all the grammatical functions.(23 : VP -> VG NP ){UP = SELF-1;IF (MEMBER(ncomp, SELF-1.ggf))THEN {UP.ncomp = SELF-2;COMPLETENESS(GF-[subj] ) }ELSE {IF (MEMBER(obj,SELF-1.ggf))THEN {UP.obj = SELF-2;COMPLETENESS(GF-[subj] ) }ELSE {UP.subj = SELF-2 }}COHERENCE(GF-[subj] }(14: CL -> NP VP){UP = SELF-2;UP.subj = SELF-1;COHERENCE(GF);COMPLETENESS(GF)}
$c:anfw <ldf> where <ldf> is a list of generated forms for not found words:
<ldf> = <df1>, <df2>, ...
Each definition, <dfN> consists of a syntactic category and a feature (between parentheses):
<dfN> = <catN>(<featureN>)
Examples:
(LU: Tajo, CAT:n, pred:Tajo)
(LU: Tajo, CAT:v, pred:Tajo)
(LU: Tajo, CAT:adj, pred:Tajo)The command is deactivated with $c:dnfw.
$t eng
$f "transfer.sp-eng"
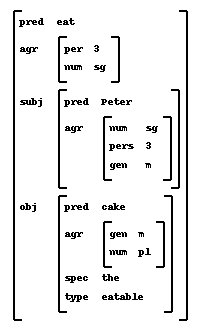
$etThe transfer phase takes an SL feature structure as input and returns a TL feature structure as output. Note that categorial information (contained in the CAT: feature) is no longer available. As in most transfer-based MT systems, two types of transfer rules may be defined in Lekta, structural transfer rules and lexical transfer rules. Lexical transfer is applied before structural transfer.
The system traverses the input f-structure, finds the first feature (say, pred:) and looks for translation rules for the that feature. If no transfer rules have been defined for that feature, it will be copied onto the target f-structure (for example, most tense features do not need translation rules).
Transfer rules are enclosed in parentheses. Each rule consists of a source item, a target item (separated by the => sign) and a set of (optional) conditions and actions. Conditions start with the reserved word WHEN and, basically, consist of a path of feature-value pairs which must be satisfied in the input f-structure. Actions start with DO, and may call other functions such as TRANSFERAS and NOTRANSFER, as illustrated below. The ordering of rules is important. Once a condition has been satisfied, the corresponding actions will be executed. Order your translation rules from most specific to most general. If none of the conditions apply, the default translation will be chosen.
Below are some examples.
% Spanish-English rules for Predicates.
FTRANSFER pred
(abrir => open)
(cambiar => change)
(cobrar => charge WHEN (ggf:[subj,obj,pobj],
pobj:(pcase:de,pred:comisión))
DO (pobj:TRANSFERAS(obj),
pobj:(pcase:NOTRANSFER()),
pobj:(pcase:of),
obj:TRANSFERAS(pobj),
obj:(spec:a))
charge )
(cerrar => close)
(decir => say)
(haber => 'there be')In the example above, the verb 'cobrar' is translated as 'charge' and triggers some special actions. The rule may be glossed as follows: if the verb cobrar contains an object and a prepositional object (that is, its subcategorization feature is ggf:[subj,obj,pobj]), the head preposition is 'de' and the head noun is 'comisión', as for example in "Cobramos 400 pesetas (obj) de comisión (pobj)" then perform the following actions: transfer the original pobj as an object, do not transfer the original preposition, transfer the original obj as a pobj and include the preposition 'of' and the determiner (spec) 'a'. The resulting translation will be: "We charge a comission (obj) of 400 pesetas (pobj)".
If the condition does not apply, translate cobrar as charge, in order to account for uses such as Cobramos 400 pesetas => We charge 400 pesetas.
Additionally, we may check whether a specific feature has a non-null value (i.e. it exists in the input feature structure with any value), as in the following example:
(número => number WHEN (spec:el,app:(quant:NONULL))
DO (spec:NOTRANSFER())
number)In this rule, número translates as number, but if it is followed by an appositional quantifier, the determiner does not translate. For example: "la número 372 => number 372".
Conversely, if we wish to check that a specific feature does not exist in the input f-structure, the reserved word NULL is used instead. NULL may also be used as a translation if we don't want to translate a specific feature. For example, the time expression "a las 7.45" should be translated as "at 7.45", where the specifier does not translate. The following rule obtains this result:
FTRANSFER spec
% a las 4.45 -> at 4.45
(el => NULL WHEN (time:yes)
the)
STRANSFER pmod
( => descr WHEN (pmod:(pcase:de,poss:NULL,dem:NULL))
DO (pmod:(pcase:NOTRANSFER( )),
pmod:(spec:NOTRANSFER()))
pmod)Simple Spanish Grammar. Version 3. Contains an analysis grammar with a transfer module.
Generation rules are built taking into account this distinction. Each generation block defines a group of GF features and HG features which must be found in the input f-structure. GF and HG features are separated by the / symbol. The next line consists of a production rule which defines the portion of the tree that will be created if this generation rule is applied. Additional conditions similar to those in the transfer phase may be added at this point.$$LANG eng% Generation Grammar$gg (GF: subj obj pobj ncomp acomp padj descr pmod mods agr)(HG: form pred pcase quant coor)
Finally, if the (optional) condition is met, the rule specifies how each of the nodes will be created. Non-terminal nodes are created through the Generate() function and terminal nodes through the Synthesis() function, as follows:
This rule creates NPs with a determiner and an ADJP if there is a specifier in the input f-structure. The triggering GF features are agr and mods, while the only relevant HG feature is pred. The determiner is identified as SELF-1 since it is the first element in the right-hand side of the production, and it will be synthesized through the application of the Synthesis() function over the value of the input spec(ifier).[agr mods]/[pred](93:NP -> det ADJP n) WHEN (spec:NONULL){ SELF-1 = Synthesis(UP.spec);SELF-2 = Generate(UP.mods);SELF-3 = Synthesis(UP.pred) }
The adjective phrase (SELF-2) will be generated recursively from the information contained in the mods feature.
[agr]/[pred]% NP is a personal pronoun(82:NP -> pron) WHEN (pred:pro){ SELF-1 = Synthesis(UP.pred) }% Adjetive phrase with a single adjective(84:ADJP -> adj) WHEN (deg:NONULL){ SELF-1 = Synthesis(UP.pred) }% NP with a determiner and a noun(86:NP -> det n) WHEN (spec:NONULL){ SELF-1 = Synthesis(UP.spec);SELF-2 = Synthesis(UP.pred) }% NP with a demonstrative determiner(88:NP -> det n) WHEN (spec:NULL,dem:NONULL){ SELF-1 = Synthesis(UP.dem);SELF-2 = Synthesis(UP.pred) }% Verb phrase with a single verb(90:VP -> v) WHEN (ggf:NONULL){ SELF-1 = Synthesis(UP.pred) }% NP with a single head noun(92:NP -> n){ SELF-1 = Synthesis(UP.pred) }
In this rule, even though four GF features have been defined, only the subject will be generated as an NP at this point. The remaining features will be managed recursively by the generation algorithm (Generate(UP)). This is just for 'cosmetic' reasons, since the input f-structure is by definition unordered and with no internal hierarchy between grammatical functions.% declarative sentences[subj agr obj pobj]/[pred](8:S -> NP VP) WHEN (stype :~ quest){ SELF-1 = Generate(UP.subj);SELF-2 = Generate(UP) }
Finally, the generation grammar finishes with the $egg symbol.% adverb phrases[]/[form] (158:ADV -> adv){ SELF-1 = Synthesis(UP.form) }
In addition to the special LU and CAT features found in the analysis lexicon, the special feature RS is also necessary. The CAT value must coincide with the terminal node being synthesized. RS stands for semantic root. Its value is the same as that of the feature calling the Synthesis function. Finally, LU will be the word returned by the synthesis algorithm. For example, given the generation instruction
and the generation entries% NP is a personal pronoun(82:NP -> pron) WHEN (pred:pro){ SELF-1 = Synthesis(UP.pred) }
the generation algorithm will return I, you, we, me or it depending on the information found in the input f-structure.(LU:I,CAT:pron,RS:pro,agr:(per:1,num:sing))(LU:you,CAT:pron,RS:pro,agr:(per:2))(LU:we,CAT:pron,RS:pro,agr:(per:1,num:pl))(LU:me,CAT:pron,RS:pro,case:dat)(LU:it,CAT:pron,RS:pro,agr:(num:sing,per:3))
Simple Spanish Grammar, version 4 contains an analysis grammar, transfer module and a generation grammar. Version 5 displays source c-structure, source f-structure, target f-structure and target c-structure in an X windows environment.
From the grammar specification, Lekta obtains a symbolic representation which is then manipulated by the parser. Computationally, it consists of a representational model which obviates search operations over the symbols and productions of the grammar and which reduces the string comparison operations between strings of characters. Functionally, the grammar compilation involves the generation of a series of tables (of coverage, derivation and adjacency) that will later control the analyzer.
The $pag command shows the grammar in use, while $ptc and $ptd display, respectively, the tables of coverage and the tables of derivation and adjacency of the grammar. These are the tables for the simple grammar of Spanish shown above.
Let's assume we have loaded the grammar above mentioned and we type the order:
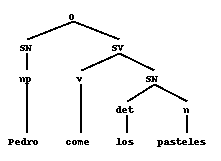
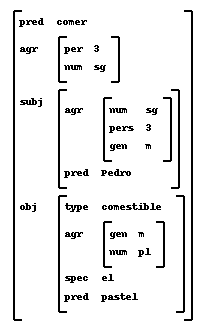
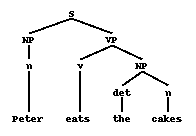
Even though the lexicon will be dealt with later, let's assume we get the following sequence back$prs(pedro come los pasteles)
corresponding to the syntactic categories of the identifiers in the input string. The parser will then work on this string until it has been reduced to any of the root symbols of the grammar (S in this example) or it would reject the input as grammatically incorrect. In this case the parser would get the following representation:np v det n
If we activate the $c:aat configuration command we will get the following output from the trace mode.
The parsing module in Lekta consists of five concentric layers, each
of which corresponds to a phase in the parsing process.
| Stage | Description | Activate | Deactivate |
|---|---|---|---|
| ex | Deterministic execution of events | $c:apex | $c:dpex |
| pr | Restriction propagation | $c:aprp | $c:dprp |
| ps | Psycholinguistic preferences | $c:appp | $c:dppp |
| hr | Heuristics | $c:aphe | $c:dphe |
| un | Verification of unification operations | $c:apun | $c:dpun |
Next, the analysis module starts. Each phase applies certain criteria to reach the execution of an event. If so, control returns to the module of creation and propagation of events, which after propagating the events which were waiting for the change that took place, and creating new applicable events, launches the analysis phase again.
This cycle will go on until the surface of analysis contains one of the root symbols of the grammar.
Therefore, each event represents a possible analysis of an interval of the analysis surface. The more events the parser can reject in the first stages of the analysis the more efficient it will be. With this goal, Lekta has been equipped with a series of success filters which each event must satisfy. Furthermore, due to the different computational costs of each filter, they are executed following a certain hierarchy associated with each stage.
At the very beginning, while events are being created, two filters are applied which can cancel the creation of the event, even though the trace mode will shows their creation and later cancellation. These filters are:
$ag
(RG:O)(GF:)(1: O -> X Y) (2:X -> a)(3:X-> a B1) (4: Y -> c)(5:Y -> B2 c) (6: B1 -> b1)(7:B2 -> b2)
$eagAssume now that we wish to parse the string (a b c) and that the lexicon generates the following string of terminal symbols for this input (a b1||b2 c). That is, a and c belong to the syntactic categories a and c, while b is ambiguous between b1 or b2.
The application of the three first stages yields the following result:
@LktTrace> InputParser> a b c
@LktTrace> CurrentParsingLayer> a b2||b1 c
@LktTrace> NewEvent> (e=1,p=2,s=a,d=1)
@LktTrace> NewEvent> (e=2,p=3,s=a,d=1)
@LktTrace> NewEvent> (e=3,p=7,s=b2,d=1)
@LktTrace> NewEvent> (e=4,p=6,s=b1,d=1)
@LktTrace> NewEvent> (e=5,p=4,s=c,d=1)
@LktTrace> NewEvent> (e=6,p=5,s=c,d=-1)
@LktRe> Input Incorrect
$ah
(1: HPATTERN (a b1||b2 c) -> ELIM-PR 6 ON-NODE 2)
$eahHeuristics are defined after the analysis grammar. They consist of a numbered list of rules. Each heuristic specifies a pattern (HPATTERN()) which must be found in any interval of the surface of analysis. If found, the rule will apply the deletion operations specified in the right-hand side of the rule. ELIM-PR n ON-NODE m states that the event associated with the production number n over the node m must be deleted. In our case, event number 4 will be deleted. The result of applying this heuristic is the following:
@LktTrace> InputParser> a b c
@LktTrace> CurrentParsingLayer> a b2||b1 c
@LktTrace> NewEvent> (e=1,p=2,s=a,d=1)
@LktTrace> NewEvent> (e=2,p=3,s=a,d=1)
@LktTrace> NewEvent> (e=3,p=7,s=b2,d=1)
@LktTrace> NewEvent> (e=4,p=6,s=b1,d=1)
@LktTrace> NewEvent> (e=5,p=4,s=c,d=1)
@LktTrace> NewEvent> (e=6,p=5,s=c,d=-1)
@LktTrace> Heuristic> (1)
@LktTrace> DeleteEvent:Heurist> (e=4,p=6)
@LktTrace> RunningEvent:ExecStage> (e=3,p=7)
@LktTrace> CurrentParsingLayer> a B2 c
@LktTrace> DeleteEvent:Deriv> (e=2,p=3) D:(B1,B2)
@LktTrace> NewEvent> (e=7,p=5,s=B2,d=1)
@LktTrace> DeleteEvent:Duplied> (e=7,p=5,s=B2,d=1) -> 6
@LktTrace> RunningEvent:ExecStage> (e=1,p=2)
@LktTrace> CurrentParsingLayer> X B2 c
@LktTrace> NewEvent> (e=8,p=1,s=X,d=1)
@LktTrace> DeleteEvent:InitLink(Prop)> (e=5,p=4)
@LktTrace> RunningEvent:ExecStage> (e=6,p=5)
@LktTrace> CurrentParsingLayer> X Y
@LktTrace> NewEvent> (e=9,p=1,s=Y,d=-1)
@LktTrace> DeleteEvent:Duplied> (e=9,p=1,s=Y,d=-1) -> 8
@LktTrace> RunningEvent:ExecStage> (e=8,p=1)
@LktTrace> CurrentParsingLayer> O
@LktRe> Input Correct
Time: indicating if the analysis correct and the timing of the process. List: analysis tree in the form of a bracketed list. Tree: analysis tree in ASCII. Incorrect: displays the parser status at the end of a incorrect input. Unification: displays the feature structures from the unifier. Graphic: In a X environment, it generates windows containing the analysis tree (c-structure) and the feature structure (f-structure) for a correct analysis. Trace: displays multiple messages regarding each module´s performance.
These devices are activated and deactivated with the following commands:
- $is: start collecting data.
- $pfs([file]): sends the statistics to a file. These include details of each production, indicating the number of events generated by each one and how many have been rejected by each filter, as well as information regarding the relative use of the production. The second block shows a summary of information regarding the level of efficiency achieved by the system as a whole.
- $ire([file]): prints only the summary section described above.
LektaII> $h
LektaII> HELP - Main Topics
Type for help about:
==== =======================
$h1 Language Specification
$h2 Translation Setup
$h3 Execution
$h4 Translation Stages
$h5 Output
$h6 Trace
$h7 Printing
$h8 Statistics
$h9 Others
TRACE
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
These options are ordered. Lower options include upper ones (i.e. unification
activates all previous parsing stages)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| $c:anfw | Activate not found words |
| $c:dnfw | Deactivate not found words |
| $c:transl SOURCE_LANG -> TARGET_LANG | Translation Source and target |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}